Edge inference is here. The market for it isn't.

In March, Comcast and NVIDIA announced a field trial that puts GPUs into about 200 of Comcast’s regional facilities: the network nodes that sit between the centralized internet and your living room. Charter announced a similar partnership around the same time, across an even larger footprint of more than 1,000 edge sites. Akamai launched its Inference Cloud across a network of more than 4,400 points of presence. Cloudflare has H100s deployed at edge inference locations and offers token-billed serverless inference on top. Nscale, working through telco partnerships, describes the same architecture in slightly different language: a distributed grid of GPU sites tied together by a control plane that routes inference requests based on latency, cost, and data residency.
The edge inference build-out has stopped being a slide in a keynote. Real GPUs are being installed in real metro facilities right now, and they will be selling capacity to real customers within the year.
What is an edge GPU-hour worth?
Which raises a question that nobody has a good answer to: what is an edge GPU-hour worth?
In cost-of-production terms, an H100 in a Comcast regional facility looks similar to an H100 in Ashburn or Quincy. The hardware is the same, the depreciation schedule is roughly the same, the power draw is in the same range. In delivered-product terms it is a completely different good. It serves a customer 5 milliseconds away rather than 50. It runs in a jurisdiction with a specific data-residency profile. It shares a chassis with a workload mix that spikes on a different schedule, in a building with a different power envelope, peered to a network that reaches different consumers. None of that is currently priced. The same GPU clears at roughly the same hourly rate whether it is sitting in a hyperscaler campus or in a cable head-end.
The argument I want to make is narrower than “the market is broken.” I’ve written before about how thin the centralized GPU pricing surface already is, and how poorly it captures the heterogeneity of what’s actually being sold. Edge breaks the same assumptions in sharper ways. Supply is fragmented across hundreds of metro sites instead of a few dozen large campuses. The relevant axes of differentiation expand to include latency band, jurisdiction, peering, and time-of-day load. And buyers stop being indifferent: an inference workload with a hard latency budget cares enormously about which facility it lands in.
What programmatic advertising solved
It is worth noticing what these edge GPUs will first be used for. Comcast’s lead announced commercial workload is a personalized video-advertising engine that customizes ads at the household level. The first thing the AI Grid will do, with a straight face, is target ads. The shape of the market it will eventually need to clear is one we have seen before.
Twenty years ago, online publishers had inventory with similar properties. Each impression had multi-dimensional features (the visitor’s geography, demographics, browsing history, the page context, the time of day, the device) that different advertisers valued differently. The inventory was fragmented across thousands of publishers, none of whom had the time or skill to negotiate every impression individually. Direct sales handled the high-value, well-understood placements. Everything else, the long tail, sat in inventory that nobody knew how to clear.
The solution that emerged was programmatic advertising. The structural insight was that the clearing mechanism had to be machine-to-machine and per-impression, because no human-paced process could handle the cardinality. Four roles emerged. Supply-side platforms (SSPs) helped publishers extract yield from inventory that varied second-to-second. Demand-side platforms (DSPs) translated advertiser goals into bids that could respond to a specific impression in a specific context. Exchanges sat in the middle and ran the auction. Data management platforms (DMPs) supplied the signal that made informed bidding possible at all. None of this replaced direct sales, which remained the right mechanism for premium, predictable inventory. It created a real-time clearing layer underneath, for everything else.
Which roles already exist, and which don’t
The question worth sitting with, for compute, is what each of these roles would look like for edge inference, and which ones already exist in some form.
The SSP role is the closest to being filled today. Both Akamai and Nscale have publicly described workload-aware routing systems that decide where each inference request should land based on latency thresholds, residency requirements, and current node utilization. Strictly speaking these are yield-optimization systems for the operator, with the auction collapsed to a single seller. They are SSPs without a market behind them.
The DSP role barely exists. There is no equivalent today of a buyer-side agent that translates “I have 50 million inference requests per day with a 100ms latency budget, GDPR residency, and a $2.50 cost ceiling per million tokens” into bids that hit multiple supply sources. Most enterprise inference buyers pick a vendor and stay with them, the way advertisers picked publishers in 1998.
The exchange role does not meaningfully exist for edge inference. The closest functioning analogues are internal: large clouds run something exchange-shaped between their own regions, but there is no neutral cross-vendor venue where an inference request from one buyer can clear against capacity from several different operators based on the request’s specific properties.
The DMP role is the one I find most interesting, partly because it is the layer that has to exist before any of the others can. Programmatic advertising could not have happened without the parallel build-out of audience and context data: the signal that buyers needed to bid intelligently. Edge compute will need its equivalent. What is actually available, where, at what spec, with what latency to which population centers, at what price, under what contract type. This is intelligence work, and the absence of it is one of the more underappreciated reasons that edge inference markets are not currently liquid. Buyers cannot price what they cannot see.
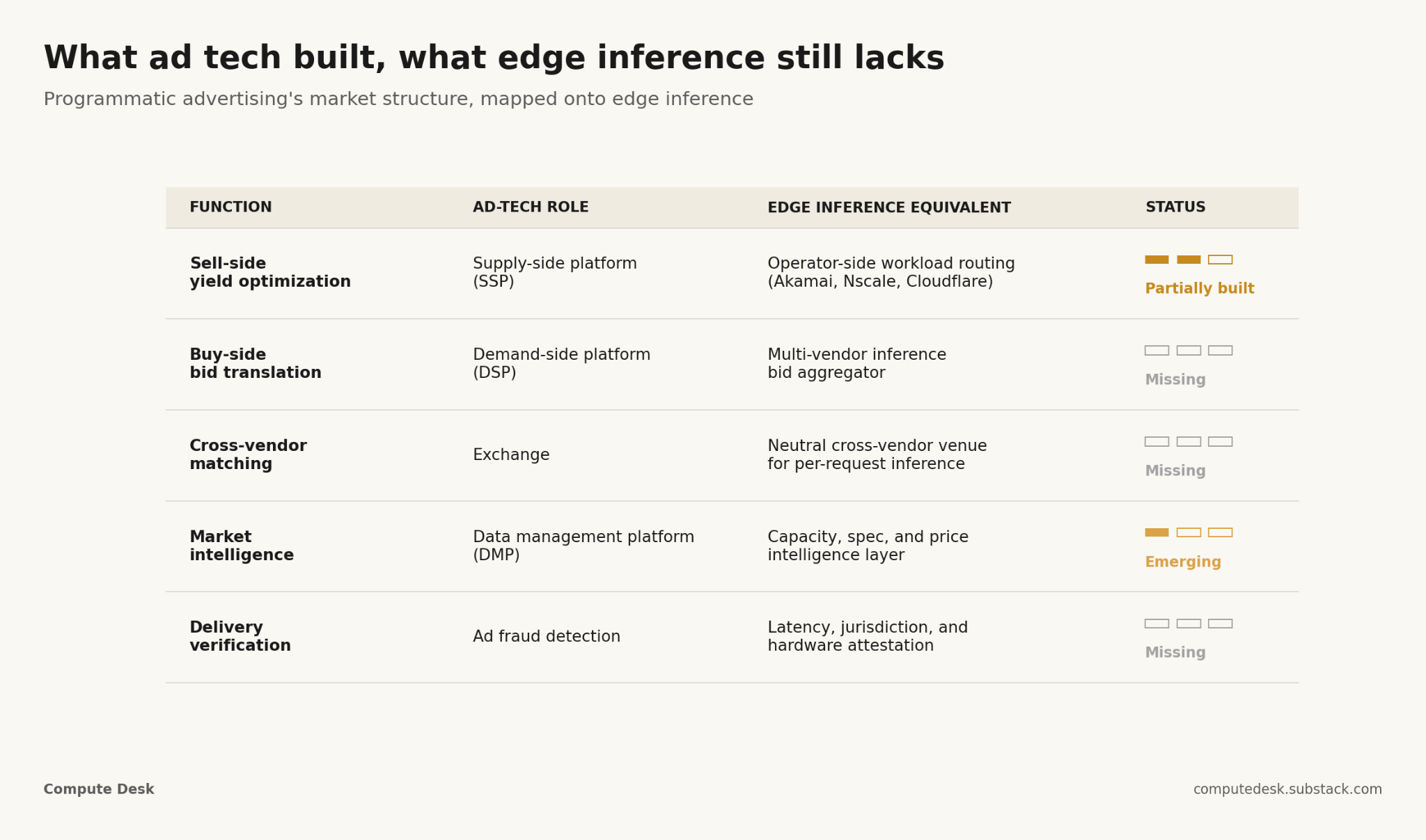
The verification layer that doesn’t exist yet
There is one more role worth naming, which programmatic eventually had to invent under duress: verification. Did the impression actually serve to a real human in the claimed geography on the claimed device? Ad fraud detection became a multi-billion-dollar industry because the answer was often no. Edge inference will face an analogous problem. Did the inference actually run within the promised latency, in the promised jurisdiction, on the promised hardware? Today there is no way to check. A neutral verification layer is going to be necessary the moment buyers start paying premiums for edge placement, because the moment the premium exists, the incentive to misrepresent the placement exists.
Either way, pricing has to change
I want to be careful here, because I don’t think the conclusion is “and therefore someone should build all of this.” Programmatic advertising is, on balance, a mixed legacy. It enabled enormous markets and also enormous waste. It funded the open web and also hollowed out a lot of journalism. It has spent twenty years grappling with transparency, fraud, and the question of who actually benefits from all the intermediation. Anyone arguing that compute should follow the same path should at least notice the parts of that path that didn’t go well.
It is also genuinely possible that edge inference will not develop an open market layer at all. The most plausible alternative is that two or three vertically-integrated edge clouds, probably some combination of hyperscaler regional builds, telco partnerships, and CDN-derived players, end up internalizing the entire stack. Buyers in that world contract with one or two of them and use the internal routing as the de facto exchange. This is closer to how cloud regions work today, and it is a perfectly viable end state.
What I am more confident about is that the current pricing infrastructure cannot survive contact with edge inference unmodified. The contract types we use (on-demand, reserved, spot) were designed for a centralized world where the relevant heterogeneity was time of commitment, not place of execution. They have no language for a workload that needs to clear against latency-banded, residency-constrained, multi-vendor supply. Whichever direction the market takes, the pricing primitives have to get richer.
The follow-up question, which is the one I find more useful in practice, is what a buyer actually wants from such a market. If you are running inference at scale today and you have thoughts on what you’d want to express in a bid, I’d be curious to hear them.
Great stuff!